自然语言处理学习2:英语分词1word_tokenize, WordPunctTokenizer, TreebankWordTokenizer , WhitespaceTokenizer等
本文共 338 字,大约阅读时间需要 1 分钟。
1. 分词word tokenize
(1) 使用nltk.word_tokenize(text), 其中"isn't"被分割为"is"和"n't"

(2)使用WordPunctTokenizer(),单词标点分割,其中"isn't"被分割为"isn","'" 和“t"

(3) 使用TreebankWordTokenizer (宾夕法尼亚州立大学 Treebank单词分割器), 其中"isn't"被分割为"is"和"n't"

(4) 使用WhitespaceTokenizer(), 空格符号分割,就是split(' ') 最简单的一个分词器。"isn't"作为一个整体,没有被分割。

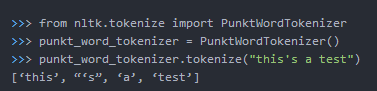
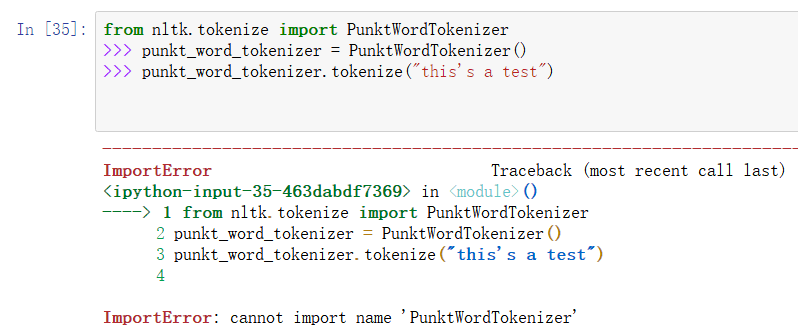
(5) PunktWordTokenizer():导入失败,未找到原因,欢迎交流讨论。
你可能感兴趣的文章
vue-element-admin关闭代码校验eslint
查看>>
cordova环境配置,将vue项目打包成apk的详细流程
查看>>
vue实现登录功能,且刷新页面不丢失数据
查看>>
vue中父组件通过props向子组件传异步值为空
查看>>
JSON序列化与反序列化在vue中的应用
查看>>
在element-ui的table组件与双大括号中使用时间处理函数
查看>>
vue给对象新增属性,页面不更新解决方法——四种方案
查看>>
vue中使用vue-visibility-change监听浏览器页面之间的切换
查看>>
vue中同时监听多个参数
查看>>
vue-cli3.0项目中使用ttf字体
查看>>
ubuntu安装nginx
查看>>
windows安装ssh服务
查看>>
Axure之入门
查看>>
Axure之动态面板
查看>>
Axure之中继器
查看>>
Axure之中继器添加行列
查看>>
Axure之中继器的上、下页按钮
查看>>
html做表格(个人简历)
查看>>
CSS样式相关小结
查看>>
vim 配置 emmet
查看>>